38 keras reuters dataset labels
Reuters | Kaggle If you publish results based on this data set, please acknowledge its use, refer to the data set by the name 'Reuters-21578, Distribution 1.0', and inform your readers of the current location of the data set." Implementing a DNN to label sentences | Keras 2.x Projects To labeling sentences, we'll use the Reuters newswire topics dataset. This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics, published by R Browse Library
Recurrent Neural Networks (RNN) with Keras | TensorFlow Core Recurrent neural networks (RNN) are a class of neural networks that is powerful for modeling sequence data such as time series or natural language. Schematically, a RNN layer uses a for loop to iterate over the timesteps of a sequence, while maintaining an internal state that encodes information about the timesteps it has seen so far. The Keras ...

Keras reuters dataset labels
› keras › keras_modelKeras - Model Compilation - tutorialspoint.com Line 1 imports minst from the keras dataset module. Line 3 calls the load_data function, which will fetch the data from online server and return the data as 2 tuples, First tuple, (x_train, y_train) represent the training data with shape, (number_sample, 28, 28) and its digit label with shape, (number_samples, ) . › datasets-in-kerasDatasets in Keras - GeeksforGeeks It consists of 11,228 newswires from Reuters, labelled over 46 topics. Just like the IMDB dataset, each wire is encoded as a sequence of word indexes (same conventions). from keras.datasets import reuters (x_train, y_train), (x_test, y_test) = reuters.load_data () Returns: x_train, x_test: list of sequences, which are lists of indexes (integers). TensorFlow - tf.keras.datasets.mnist.load_data - Loads the MNIST dataset. tf.keras.datasets.mnist.load_data ( path= 'mnist.npz' ) This is a dataset of 60,000 28x28 grayscale images of the 10 digits, along with a test set of 10,000 images. More info can be found at the MNIST homepage. Returns Tuple of NumPy arrays: (x_train, y_train), (x_test, y_test).
Keras reuters dataset labels. Datasets - Keras The tf.keras.datasets module provide a few toy datasets (already-vectorized, in Numpy format) that can be used for debugging a model or creating simple code examples. If you are looking for larger & more useful ready-to-use datasets, take a look at TensorFlow Datasets. Available datasets MNIST digits classification dataset load_data function keras/reuters.py at master · keras-team/keras · GitHub This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this [GitHub discussion] ( ) for more info. › api_docs › pythontf.keras.utils.text_dataset_from_directory | TensorFlow v2.9.1 Overview; LogicalDevice; LogicalDeviceConfiguration; PhysicalDevice; experimental_connect_to_cluster; experimental_connect_to_host; experimental_functions_run_eagerly Text Classification in Keras (Part 1) — A Simple Reuters News ... import keras from keras.datasets import reuters Using TensorFlow backend. (x_train, y_train), (x_test, y_test) = reuters.load_data (num_words=None, test_split=0.2) word_index = reuters.get_word_index (path="reuters_word_index.json") print ('# of Training Samples: {}'.format (len (x_train))) print ('# of Test Samples: {}'.format (len (x_test)))
Datasets - Keras Documentation - faroit Dataset of 50,000 32x32 color training images, labeled over 100 categories, and 10,000 test images. Usage: from keras.datasets import cifar100 (X_train, y_train), (X_test, y_test) = cifar100.load_data(label_mode='fine') Return: 2 tuples: X_train, X_test: uint8 array of RGB image data with shape (nb_samples, 3, 32, 32). PDF Introduction to Keras - AIoT Lab from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000) Decode the News •Decode the word ID list back into English 39 word_index = reuters.get_word_index() reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) keras source: R/datasets.R R/datasets.R defines the following functions: as_sequences_dataset_list as_dataset_list dataset_boston_housing dataset_fashion_mnist dataset_mnist dataset_reuters_word_index dataset_reuters dataset_imdb_word_index dataset_imdb dataset_cifar100 dataset_cifar10 keras实现路透社新闻主体的分类_智慧的旋风的博客-CSDN博客 keras实现路透社新闻主体的分类 参考书目:《Python深度学习》。 Just for fun! ! ! import keras from keras.datasets import reuters import matplotlib.pyplot as plt import numpy as np 1 2 3 4 Using TensorFlow backend. 1 加载路透社数据集 (train_data,train_label),(test_data,test_label)=reuters.load_data(num_words=10000) 1 1.1 分割训练集和测试集(切片)
Is there a dictionary for labels in keras.reuters.datasets? I managed to get an AI running that predicts the classes of the reuters newswire dataset. However, I am desperately looking for a way to convert my predictions (intgers) to topics. There has to be a dictionary -like the reuters.get_word_index for the training data- that has 46 entries and links each integer to its topic (string). Thanks for ... Reuters newswire classification dataset - Keras This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this github discussion for more info. Each newswire is encoded as a list of word indexes (integers). How to show topics of reuters dataset in Keras? - Stack Overflow Associated mapping of topic labels as per original Reuters Dataset with the topic indexes in Keras version is: ['cocoa','grain','veg-oil','earn','acq','wheat','copper','housing','money-supply', 'coffee','sugar','trade','reserves','ship','cotton','carcass','crude','nat-gas', ... TensorFlow - tf.keras.datasets.reuters.load_data - Loads the Reuters ... This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this github discussion for more info. Each newswire is encoded as a list of word indexes (integers).
Where can I find topics of reuters dataset #12072 - GitHub In Reuters dataset, there are 11228 instances while in the dataset's webpage there are 21578. Even in the reference paper there are more than 11228 examples after pruning. Unfortunately, there is no information about the Reuters dataset in Keras documentation. Is it possible to clarify how this dataset gathered and what the topics labels are?

What is keras datasets? | classification and arguments - EDUCBA Reuters classification dataset for newswire is somewhat like IMDB sentiment dataset irrespective of the fact Reuters dataset interacts with the newswire. It can consider dataset up to 11,228 newswires from Reuters with labels up to 46 topics. It also works in parsing and processing format. # Fashion MNIST dataset (alternative to MNIST)

Multiclass Classification and Information Bottleneck — An example using ... The Reuters dataset is a set of short newswires sorted into 46 mutually exclusive topics. Reuters published it in 1986. This dataset is used widely for text classification. There are 46 topics, where some topics are represented more than others. However, each topic contains at least ten examples in the training set.

Custom Data Augmentation in Keras
keras: Where can I find topics of reuters dataset | gitmotion.com In Reuters dataset, there are 11228 instances while in the dataset's webpage there are 21578. Even in the reference paper there are more than 11228 examples after pruning. Unfortunately, there is no information about the Reuters dataset in Keras documentation. Is it possible to clarify how this dataset gathered and what the topics labels are?
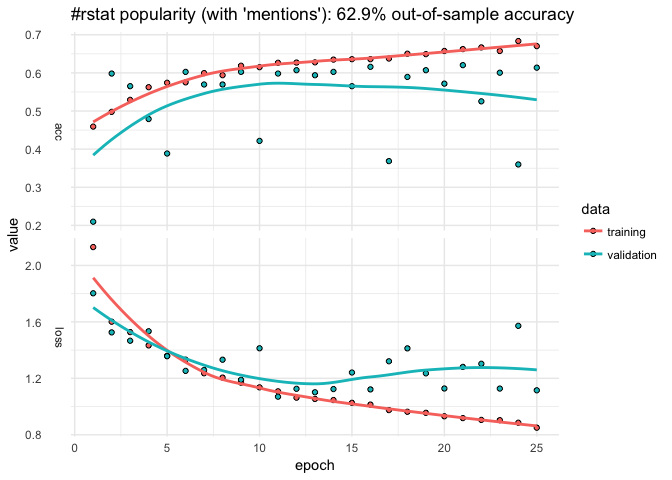
RStudio AI Blog: Analyzing rtweet Data with kerasformula
Datasets - keras-contrib - Read the Docs Dataset of 60,000 28x28 grayscale images of 10 fashion categories, along with a test set of 10,000 images. This dataset can be used as a drop-in replacement for MNIST. The class labels are: Usage: from keras.datasets import fashion_mnist (x_train, y_train), (x_test, y_test) = fashion_mnist.load_data () Returns: 2 tuples:

github.com › kk7nc › Text_ClassificationGitHub - kk7nc/Text_Classification: Text Classification ... from keras. layers import Input, Dense from keras. models import Model # this is the size of our encoded representations encoding_dim = 1500 # this is our input placeholder input = Input (shape = (n,)) # "encoded" is the encoded representation of the input encoded = Dense (encoding_dim, activation = 'relu')(input) # "decoded" is the lossy ...
datagen.flow_from_directory classes (class_indices) do not correspond to model.predict class ...
Tutorial On Keras Tokenizer For Text Classification in NLP To do this we will make use of the Reuters data set that can be directly imported from the Keras library or can be downloaded from Kaggle. This data set contains 11,228 newswires from Reuters having 46 topics as labels. We will make use of different modes present in Keras tokenizer and will build deep neural networks for classification. THE BELAMY

Python keras.datasets.reuters.load_data() Examples def load_retures_keras(): from keras.preprocessing.text import tokenizer from keras.datasets import reuters max_words = 1000 print('loading data...') (x, y), (_, _) = reuters.load_data(num_words=max_words, test_split=0.) print(len(x), 'train sequences') num_classes = np.max(y) + 1 print(num_classes, 'classes') print('vectorizing sequence …

Topic Analysis of News Articles. In this article, my main goal is to… | by Aishwarya Bose ...
基于Kears的Reuters新闻分类_csdn0006的博客-CSDN博客_reuters数据集 Reuters数据集发布在1986年,一系列短新闻及对应话题的数据集;是文本分类问题最常用的小数据集。 和IMDB、MNIST数据集类似,Reuters数据集也可以通过Keras直接下载。 加载数据集 from keras.datasets import reuters (train_data,train_labels), (test_data, test_labels) = reuters.load_data (num_words=10000) 1 2 3 有8982条训练集,2246条测试集。 每个样本表示成整数列表。

数据增强——Keras Image Data Augmentation 各参数详解_WK785456510的博客-CSDN博客
keras: keras/datasets/reuters.py - 2.4.0 vs. 2.6.0 changes | Fossies Diffs This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged

Data Augmentation tasks using Keras for image data | by Ayman Shams | Medium
Keras dataset의 load_data함수에서 발생한 ValueError 문제해결하기 검증된 코드이므로 실행이 잘 되어야할텐데 ValueError가 발생하므로 문제를 해결해야 하는 상황입니다. 보다 구체적으로 아래의 간단한 코드를 실행할 때 발생되는 에러를 수정해서 코드가 동작하도록 수정합니다. from keras. datasets import imdb ( train_data, train_labels ...

TensorFlow - tf.keras.datasets.mnist.load_data - Loads the MNIST dataset. tf.keras.datasets.mnist.load_data ( path= 'mnist.npz' ) This is a dataset of 60,000 28x28 grayscale images of the 10 digits, along with a test set of 10,000 images. More info can be found at the MNIST homepage. Returns Tuple of NumPy arrays: (x_train, y_train), (x_test, y_test).

Image Data Augmentation with Keras
› datasets-in-kerasDatasets in Keras - GeeksforGeeks It consists of 11,228 newswires from Reuters, labelled over 46 topics. Just like the IMDB dataset, each wire is encoded as a sequence of word indexes (same conventions). from keras.datasets import reuters (x_train, y_train), (x_test, y_test) = reuters.load_data () Returns: x_train, x_test: list of sequences, which are lists of indexes (integers).

ResNet_50_model_keras | Kaggle
› keras › keras_modelKeras - Model Compilation - tutorialspoint.com Line 1 imports minst from the keras dataset module. Line 3 calls the load_data function, which will fetch the data from online server and return the data as 2 tuples, First tuple, (x_train, y_train) represent the training data with shape, (number_sample, 28, 28) and its digit label with shape, (number_samples, ) .

Understanding and Coding a ResNet in Keras - Towards Data Science
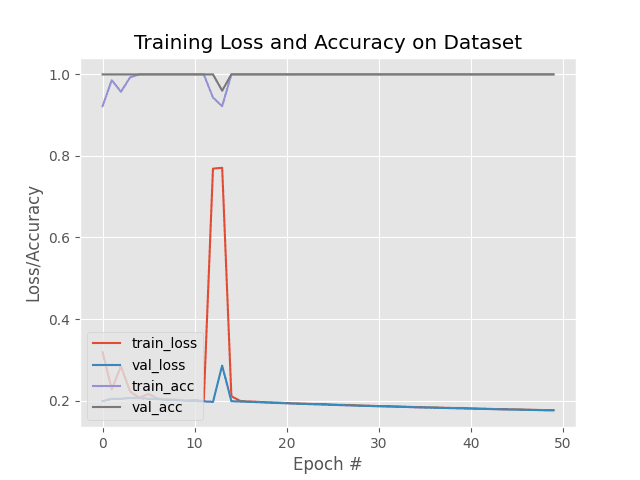
Keras ImageDataGenerator and Data Augmentation - PyImageSearch

Post a Comment for "38 keras reuters dataset labels"